Biography
Haoran Zhao is a master student at Northwestern University majoring in Computer Science.
He is incredibly insightful when confronting challenges and works immediately to solve them. He is always open minded to new opportunities and is more than able to address complex situations with strategy and confidence.
Download my resumé.
Interests
- Machine Learning
- Deep Learning
- Data Analysis
- LLMs
- AI4Science
Education
-
Master of Science in Computer Science, 2025
Northwestern University
-
Bachelor of Science in Data Science, 2023
Drexel University
-
Bachelor of Engineering in Computer Science, 2021
Lanzhou University
Skills
python
100%
MySQL
90%
R
70%
C/C++
60%
JavaScript
60%
Statistics
100%
Machine Learning
100%
Cloud Computing
80%
Git/Bash
80%
Experience
Research Assistant
Responsibilities include:
- Participated in the NSF Institute for Data Driven Dynamical Design project
- Built efficient pipeline to collect scholarly literature in material science from various publishers
- Participated in team meetings and collaborate on scholarly and scientific output
Data Engineering Co-Op
Responsibilities include:
- Participated in the design, development, and enhancement of the company’s data platform.
- Processed data requests submitted by different departments of the company.
- Participated in developing innovative solutions that gave Vivid Seats Inc. a competitive advantage and technology improvements on the data engineering team.
Team Leader for the Blockly Module
Lanzhou University DSLab
Participated in the Google Open Source Blockly Teaching Cases Data Systems project.
Data Scientist Internship
Hangzhou Yunge Data Technology Co., Ltd
Participated in the development of Instant messenger-based roadside assistance system.
Recent Posts


Projects
*





Featured Publications

Recent Publications
(2024).
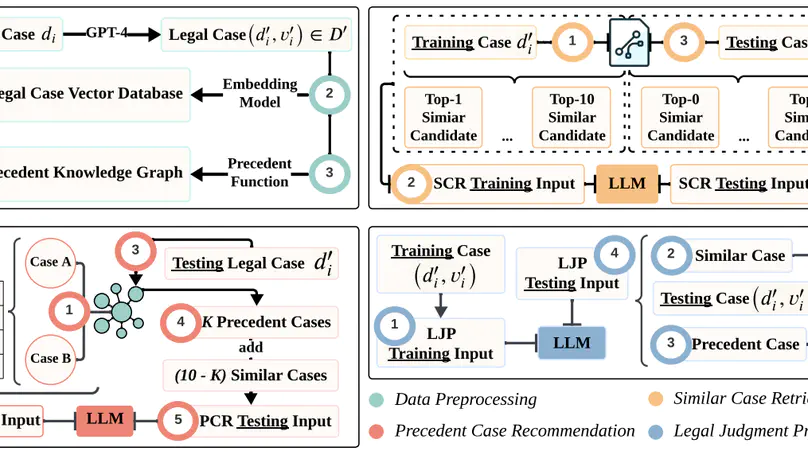
LawLLM: Law Large Language Model for the US Legal System.
Proceeding of CIKM 2024 Applied Research Paper track.
(2022).
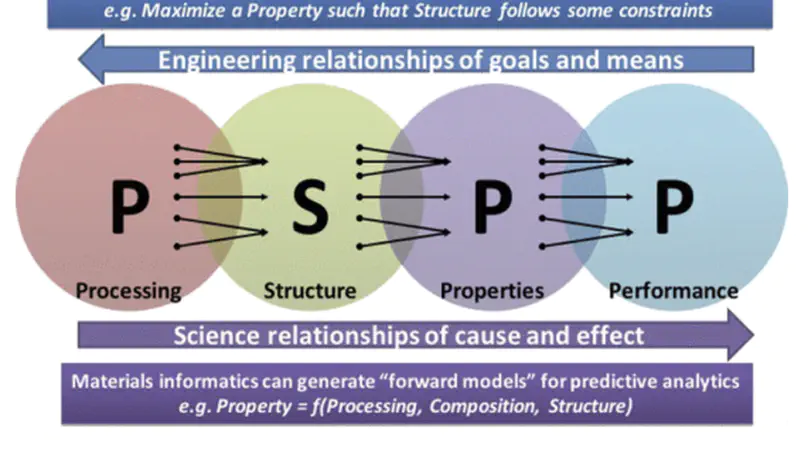
Materials Science Ontology Design with an Analytico-Synthetic Facet Analysis Framework.
Proceeding of MTSR 2022.
(2021).
Computer dynamic model and time series prediction of air by LSTM recurrent neural network.
In ICECCE 2021.
Contact
- HaoranZhao2024@u.northwestern.edu
- 445 208 8781
- 1720 Central St, Evanston, IL 60201